
你跟 AI 聊天時的每一次修正、每一次追問、每一次重新描述——這些全都是訓練訊號。OpenClaw-RL 讓 Agent「越用越聰明」不再是口號。
核心洞見
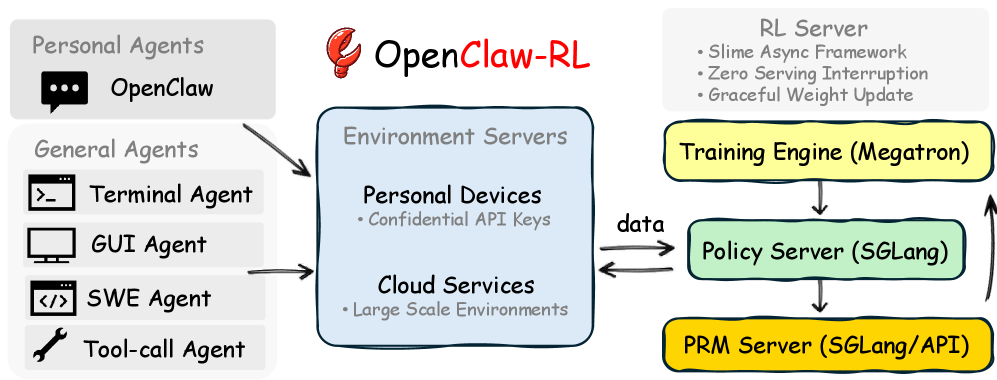
目前的 AI Agent 訓練大多是「離線」的:先收集資料、標註、訓練、部署。但 OpenClaw-RL 發現一件事——每次 Agent 執行動作後,環境的回應(使用者回覆、終端輸出、GUI 變化)本身就是最好的學習素材。
對話、終端執行、GUI 操作、軟體工程任務、工具呼叫——這些不是五個不同的訓練問題,而是同一個訓練迴圈的五種互動方式。統一起來,Agent 就能從所有互動中同時學習。
兩種學習訊號
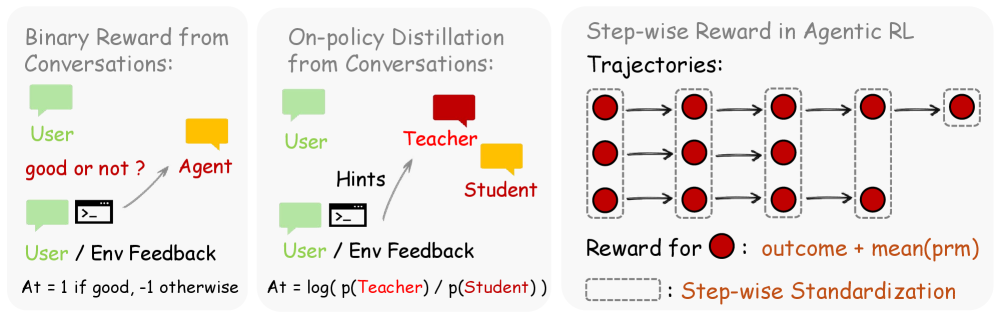
環境回應包含兩種資訊:「評價訊號」——這個動作做得好不好(由 PRM 評審提取為數值獎勵);「指導訊號」——這個動作應該怎麼改(透過 Hindsight-Guided On-Policy Distillation 從下一狀態中還原修正提示)。
指導訊號比純粹的「好/不好」更有用。它不只告訴 Agent 做錯了,還告訴它「應該怎麼做」。這就像主管不只打分數,還會告訴你具體改進方向。
非同步架構
最厲害的設計是完全非同步:模型同時在服務使用者請求、PRM 評審在評估互動品質、訓練器在更新策略——三者並行,零協調開銷。
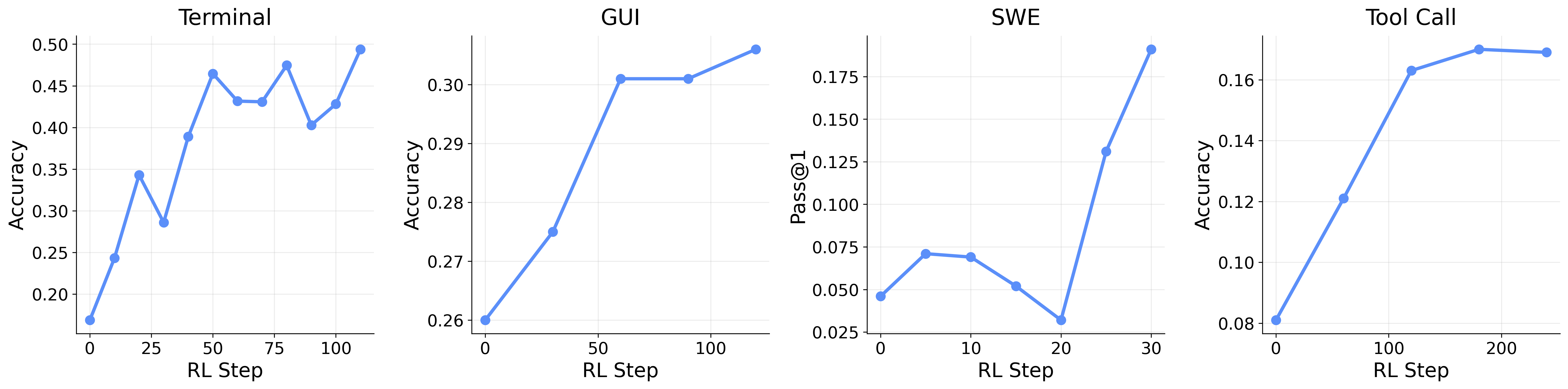
這意味著 Agent 不需要「停下來學習」。它邊工作邊進化,使用者完全無感。你只會發現它今天比昨天更懂你。
對你有什麼影響?
如果你正在打造 AI 產品或個人 Agent,OpenClaw-RL 描繪了一個未來:你的 Agent 不需要你手動調 Prompt 就會越來越好。使用者的每次互動都是免費的訓練資料。
這也意味著「個人化」不再只是記住你的偏好,而是從你的使用習慣中學習到更好的行為模式。Agent 的競爭力不只在基礎模型,更在於它累積了多少互動經驗。
OpenClaw-RL 把「用的越多越聰明」從概念變成框架。統一所有互動為訓練訊號,Agent 在被使用的過程中自動進化——這是個人 AI 助手的未來。
更多 AI 新聞
追蹤 IG 第一時間收到 AI 新聞推播。