
AI Agent 越來越會操作電腦了,但怎麼判斷它有沒有真的完成任務?這篇論文的答案是:看影片。
問題是什麼?
Computer-Using Agents(CUA)是能直接操作電腦的 AI——點擊、打字、開應用程式。但有個大問題:你怎麼知道它真的完成了你交代的任務?檢查最終畫面不夠,因為過程中可能走了捷徑或犯了錯。讀 Agent 的內部推理也不靠譜,因為它可能「自以為」做對了。
這篇論文提出一個直覺的方法:錄下 Agent 操作電腦的螢幕影片,然後訓練另一個 AI 來看影片判斷任務是否成功。就像主管看員工的螢幕錄影來評估工作品質。
他們怎麼做?
團隊建了一個 53,000 筆資料的資料集叫 ExeVR-53k,每筆包含:一段操作影片、對應的任務指令、以及成功或失敗的標註。為了讓模型學會分辨「真的完成」和「看起來像完成」,他們用了一個聰明的手法:對抗式指令翻譯——把成功的影片配上微妙修改的指令,讓它變成「失敗」案例。
另一個技術亮點是時空 Token 剪枝。操作影片很長、解析度又高,直接丟給模型會爆記憶體。他們的方法會自動找出影片中「有變化的」關鍵區域,把不重要的部分裁掉,大幅降低運算量。
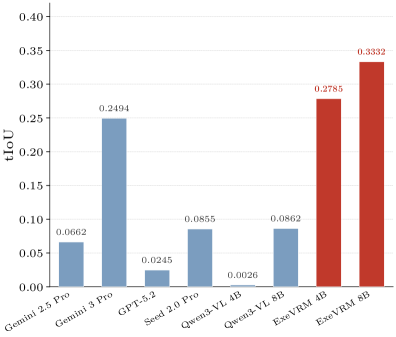
效果有多強?
ExeVRM 8B(只有 80 億參數的開源模型)達到 84.7% 準確率和 87.7% 召回率。重點來了:它打贏了 GPT-5.2 和 Gemini-3 Pro 這些商業閉源巨頭。一個 8B 的小模型靠專門訓練就能超越通用大模型,這很有意義。
更厲害的是它能做「時間歸因」——不只告訴你任務成功或失敗,還能指出「影片的哪個時間點」是關鍵轉折。這對除錯和改進 Agent 非常有用。
對你有什麼影響?
如果你在用 AI Agent 做自動化工作(比如用 browser-use、Computer Use),這個研究告訴你:未來可以用「錄影回放 + AI 判讀」來自動驗證 Agent 的工作品質。不用寫複雜的測試腳本,錄個影片讓 AI 看就好。
更大的趨勢是:AI 系統正在學會「自我監督」。一個 AI 做事,另一個 AI 看影片打分數。這種分工模式會讓 AI 自動化變得更可靠。
用影片評估 AI Agent 的任務完成度,8B 小模型打贏商業巨頭。這代表「AI 監督 AI」的時代正在到來,而且不需要天價算力。
更多 AI 新聞
追蹤 IG 第一時間收到 AI 新聞推播。