
大模型一定要 GPU 才能跑?Bitnet.cpp 證明了:只要模型夠「精簡」,你的筆電 CPU 就是最好的推論引擎。
什麼是 1-bit 大模型?
傳統大模型的每個參數用 16-bit 或 32-bit 浮點數儲存。BitNet b1.58 把每個參數壓縮到只有三個值:-1、0、+1(所以叫「ternary」三元模型)。這不是訓練完再壓縮,而是從頭用這種格式訓練——所以品質幾乎不損失。
Bitnet.cpp 就是讓這種 1-bit 模型能在普通 CPU 上高效運行的推論框架。微軟研究院發表,已被 ACL 2025 接收。
核心技術
關鍵創新是兩套矩陣乘法內核。第一套「TL」用查表法(Lookup Table)——既然權重只有三個值,乾脆不算了,直接查表。透過鏡像合併和符號位拆分,查表大小壓到最小。
第二套「I2_S」用打包解包技巧,在 int16 精度下做加法,完全無量化損失。兩套方法在不同硬體上各有優勢,框架會自動選擇最快的。
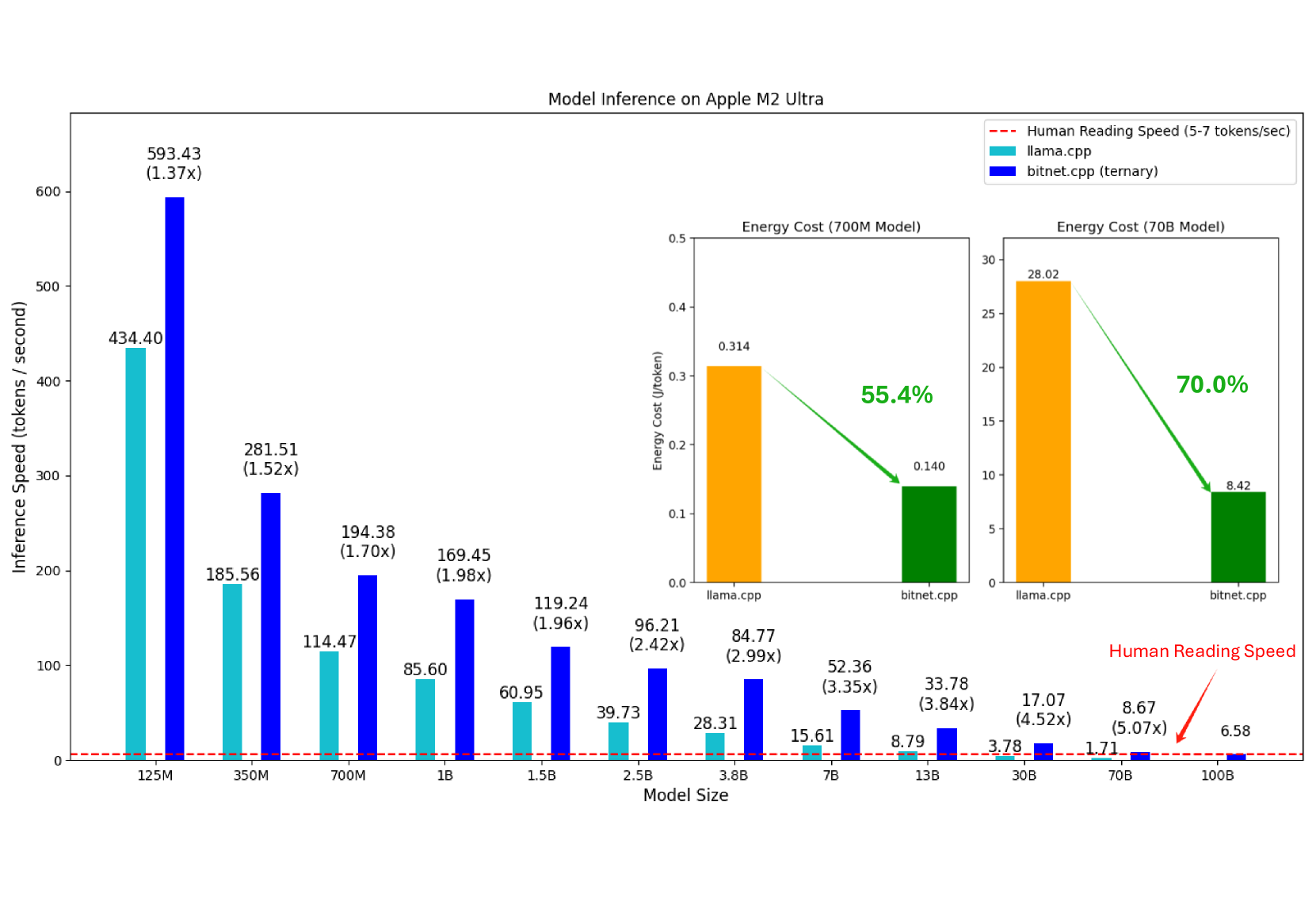
效果有多猛?
100B 參數的模型在 Apple M2 Ultra 上跑出 5-7 tokens/sec——剛好是人類閱讀速度。比 float16 快 6.17 倍,比之前最好的低位元方案快 2.32 倍。能耗降低最高 82%。
而且是完全無損推論:WikiText2 困惑度維持在 11.29,跟 float16 完全一樣。快、省、還不掉品質。
對你有什麼影響?
這意味著 AI 推論不再是 GPU 大廠的專利。任何人的筆電、手機、甚至嵌入式裝置都可以跑大模型。想像一下:離線的 AI 助手、不需要網路的翻譯、本地的程式碼補全——全部在你的裝置上完成,不用上傳資料到雲端。
對隱私敏感的場景(醫療、法律、企業內部)來說,這是突破性的。你可以擁有一個強大的 AI,但資料完全不出你的電腦。
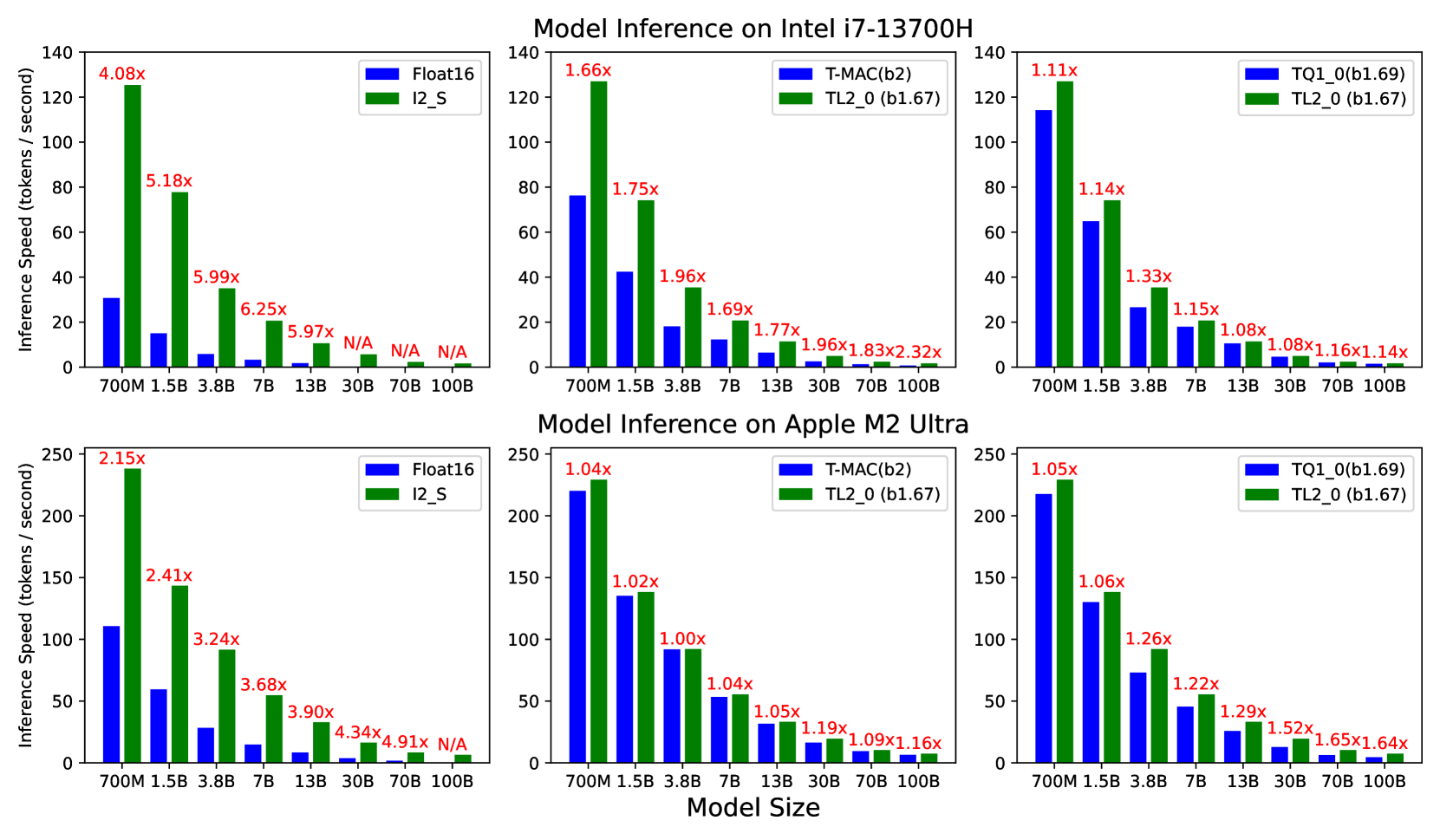
Bitnet.cpp 讓 100B 大模型在筆電 CPU 上跑出人類閱讀速度,無損品質、省電 82%。AI 推論的民主化,從這裡開始。
更多 AI 新聞
追蹤 IG 第一時間收到 AI 新聞推播。